

Untuk meningkatkan kecepatan pengembangan aplikasi bertenaga large language model (LLM), Anda dapat mempertimbangkan Inference-as-a-Service. Mari kita bahas bagaimana pendekatan ini dapat membantu Anda!
Apa itu Inference-as-a-Service?
Dengan “Inference-as-a-Service”, aplikasi perusahaan berinteraksi dengan model pembelajaran mesin (dalam hal ini, LLM), dengan overhead operasional yang rendah. Ini berarti Anda dapat menjalankan kode untuk berinteraksi dengan LLM tanpa berfokus pada infrastruktur.
Cloud Run sebagai Inference-as-a-Service
Cloud Run adalah platform serverless container milik Google Cloud yang memanfaatkan runtime kontainer tanpa harus memikirkan infrastrukturnya. Inilah sebabnya mengapa Cloud Run cocok untuk menjalankan aplikasi bertenaga LLM–Anda hanya membayar saat layanan berjalan.
Ada banyak cara untuk menggunakan Cloud Run untuk melakukan inferensi dengan LMM. Hari ini, kita akan membahas cara hosting LLM terbuka di Cloud Run dengan GPU.
Pertama, kenali Vertex AI. Vertex AI adalah platform AI/ML lengkap milik Google Cloud yang menawarkan primitif yang diperlukan bagi perusahaan untuk melatih dan menyajikan model ML. Di Vertex AI, Anda dapat mengakses Model Garden, yang menawarkan lebih dari 160 model dasar termasuk model pihak pertama (Gemini), pihak ketiga, dan model sumber terbuka.
Baca juga: Google Cloud Directory Sync Kini Menyediakan Setelan Pengelolaan Akun
Sementara Vertex AI menyediakan titik akhir inferensi terkelola, Google Cloud juga menawarkan tingkat fleksibilitas baru dengan GPU untuk Cloud Run. Hal ini pada dasarnya mengubah paradigma inferensi. Mengapa? Karena alih-alih hanya mengandalkan infrastruktur Vertex AI, Anda sekarang dapat mengontainerisasi LLM (atau model lain) dan menerapkannya langsung ke Cloud Run.
Ini berarti Anda tidak hanya membangun lapisan tanpa server di sekitar LLM, tetapi Anda menghosting LLM itu sendiri pada arsitektur tanpa server. Model diskalakan ke nol saat tidak aktif, dan diskalakan secara dinamis sesuai permintaan, mengoptimalkan biaya dan performa. Dengan akselerasi GPU, layanan Cloud Run dapat siap untuk inferensi dalam waktu kurang dari 30 detik.
Sesuaikan LLM Anda dengan RAG
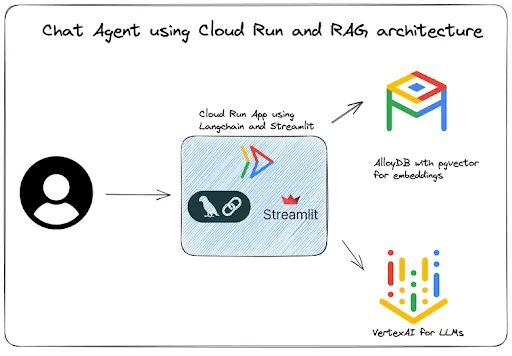
Photo Credit: Google Cloud
Selain menjalankan dan menskalakan LLM, sering kali untuk perlu menyesuaikan respons dengan domain atau kumpulan data tertentu. Di sinilah Retrieval-Augmented Generation (RAG) berperan, komponen inti untuk memperluas pengalaman LLM Anda – dan komponen yang dengan cepat menjadi standar untuk kustomisasi kontekstual.
Baca juga: Meningkatkan Interpretabilitas LLM dengan Evaluation Service Vertex AI
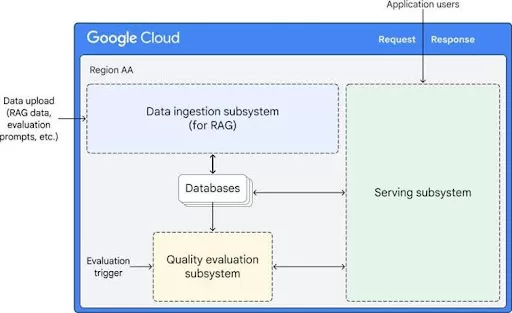
Photo Credit: Google Cloud
Ada beberapa cara Inference-as-a-Service berperan. Misalnya, saat melihat arsitektur ini, kita melihat bahwa Cloud Run menangani logika inferensi inti, mengatur interaksi antara Vertex AI dan AlloyDB. Secara khusus, ia berfungsi sebagai jembatan untuk mengambil data dari AlloyDB dan meneruskan kueri ke Vertex AI, yang secara efektif mengelola seluruh aliran data RAG.
Baca juga: Layanan Zero-touch Enrollment untuk Perangkat Chrome OS
Untuk memulai, kunjungi codelab ini yang akan menunjukkan cara membangun AI Python Application generatif menggunakan Cloud Run. Jika Anda ingin menguji Cloud Run dengan GPU, cobalah codelab ini.
Kemudahan Cloud Run sebagai Inference-as-a-Service ini bisa Anda nikmati cukup dengan berlangganan Google Cloud yang kini telah tersedia di EIKON Technology. Untuk informasi lebih lanjut, silakan hubungi kami di sini!