
BigQuery BI Engine adalah sebuah sistem analisis in-memory untuk BigQuery yang saat ini memproses lebih dari 2 miliar kueri per bulan dan akan terus bertambah. Penggunaan BI Engine sangatlah mudah, Anda cukup membuat reservasi memori pada project yang menjalankan BigQuery, dan itu akan meng-cache data serta menggunakan optimalisasi.
Artikel kali ini akan membahas bagaimana BI Engine memberikan performa yang sangat cepat untuk kueri BigQuery Anda dan apa yang dapat dilakukan pengguna untuk memanfaatkan potensinya.
Optimalisasi BI Engine
Dua pilar utama BI Engine adalah in-memory data caching dan pemrosesan vektor. Optimalisasi lainnya termasuk pemangkasan metadata CMETA, pemrosesan simpul tunggal, dan optimalisasi gabungan untuk tabel yang lebih kecil.
Baca juga: Penyempurnaan Facet Google Cloud Search, Seperti Apa?
Bantu BigQuery dalam pengelolaan data
BI Engine menggunakan filter kueri untuk mempersempit sekumpulan blok yang akan dibaca. Oleh karenanya, mempartisi dan mengelompokkan data Anda akan mengurangi jumlah data yang akan dibaca, latensi, dan penggunaan slot.
Kedalaman kueri
BI Engine saat ini mempercepat tahapan kueri yang membaca data dari tabel, yang biasanya merupakan bagian dari eksekusi kueri. Artinya, hampir setiap kueri akan menggunakan beberapa slot BigQuery.
Untuk memitigasi hal ini, BI Engine mencoba mendorong komputasi sebanyak mungkin ke tahap pertama. Misalnya, Query1 dari benchmark TPCH 10G relatif sederhana. Kedalamannya 3 tahap dengan filter dan agregasi efisien yang memproses 30 juta baris, namun hanya menghasilkan 1.
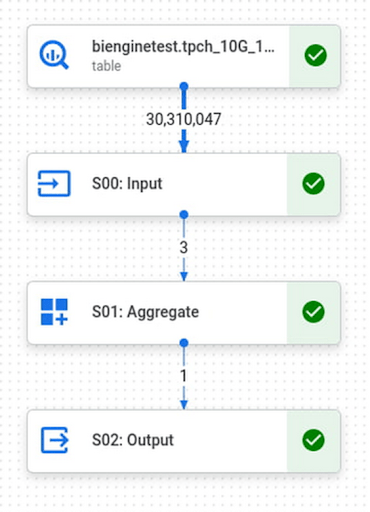 Photo Credit: Google Cloud Blog
Photo Credit: Google Cloud Blog
Menjalankan kueri ini di BI Engine, Anda dapat melihat bahwa kueri lengkap membutuhkan waktu 215 ms dengan tahap “S00: Input” yang dipercepat oleh BI Engine hingga menjadi 26 ms saja.

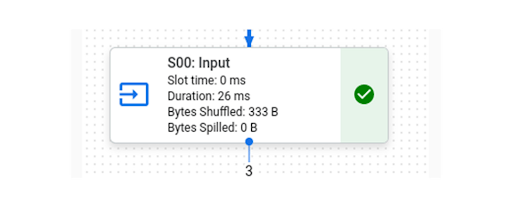 Photo Credit: Google Cloud Blog
Photo Credit: Google Cloud Blog
Menjalankan kueri yang sama di BigQuery menghasilkan 583 md, dengan “S00: Input” membutuhkan waktu 229 md saja.

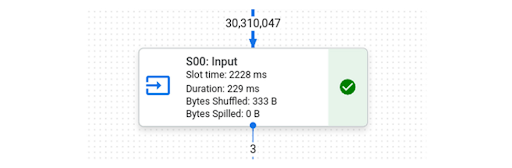 Photo Credit: Google Cloud Blog
Photo Credit: Google Cloud Blog
Itu artinya, waktu proses tahap “S00: Input” turun hingga 8x, tapi kueri keseluruhan tidak menjadi 8x lebih cepat. Sebab, dua tahap lainnya tidak dipercepat dan waktu prosesnya tetap kurang lebih sama. Berikut gambaran perincian antar tahapannya:
 Photo Credit: Google Cloud Blog
Photo Credit: Google Cloud Blog
Joins
BI mempercepat tahapan “leaf” kueri. Namun, ada satu pola yang sangat umum digunakan dalam alat BI yang dioptimalkan oleh BI Engine. Saat itulah, satu tabel “fact” besar digabungkan dengan satu atau lebih tabel “dimension” yang lebih kecil. Kemudian BI Engine dapat melakukan banyak gabungan, semuanya dalam satu tahap “leaf”, menggunakan apa yang disebut sebagai strategi eksekusi gabungan “broadcast”.
Baca juga: Storage Transfer Service Google Cloud Kini Mendukung Kapabilitas Replikasi Real- Time
Selama broadcast join, tabel fakta dipecah untuk dieksekusi secara paralel pada beberapa node, sedangkan tabel dimensi dibaca pada setiap node secara keseluruhan.
Misalnya, Anda menjalankan Query 3 dari benchmark TPC-DS 1G. Tabel faktanya adalah store_sales dan tabel dimensinya adalah date_dim dan item. Di BigQuery, tabel dimensi akan dimuat ke pengacakan terlebih dahulu, lalu ke tahap “S03: Join+”. Untuk setiap bagian paralel store_sales, akan membaca semua kolom yang diperlukan dari tabel dua dimensi untuk digabungkan.
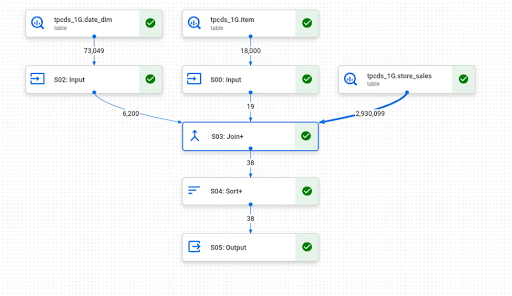 Photo Credit: Google Cloud Blog
Photo Credit: Google Cloud Blog
Dengan BI Engine, katakanlah dua node akan memproses kueri karena tabel store_sales terlalu besar untuk pemrosesan satu node. Pada gambar di bawah, Anda dapat melihat bahwa kedua node akan memiliki operasi yang serupa—membaca data, memfilter, membuat tabel pencarian, dan kemudian melakukan penggabungan. Meski hanya sebagian data untuk tabel store_sales, yang diproses pada masing-masing tabel, semua operasi pada tabel dimensi akan diulang.
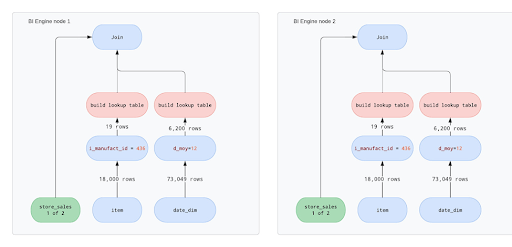 Photo Credit: Google Cloud Blog
Photo Credit: Google Cloud Blog
Baca juga: Melihat Contoh Penerapan Google Distributed Cloud Edge Appliance
Bisa disimpulkan bahwa untuk mengoptimalkan penggunaan BI Engine, pastikan untuk memfilter dan mengagregasi data sebanyak mungkin di awal kueri. Dorong filter dan komputasi ke dalam BI Engine. Kueri dengan jumlah tahapan yang sedikit akan mendapat akselerasi terbaik.
Penggunaan join terkadang mahal, namun BI Engine mungkin akan sangat efisien dalam mengoptimalkan kueri skema biasa. Mempartisi dan/atau mengelompokkan tabel bermanfaat untuk membatasi jumlah data yang akan dibaca.
BigQuery BI Engine merupakan mesin analitik data untuk menjalankan data yang disimpan di BigQuery. Mesin ini berjalan di ekosistem Google Cloud, menawarkan pengalaman yang lebih seamless, cepat, dan tentunya aman.
Dapatkan layanan komputasi awan Google Cloud melalui EIKON Technology. Kami merupakan partner resmi Google Cloud Indonesia, yang menghadirkan produk berlisensi dengan layanan konsultasi penerapan komprehensif. Untuk informasi lebih lanjut, hubungi kami di sini!

