

Banyak pelanggan membangun saluran data streaming untuk menyerap, memproses, dan kemudian menyimpan data untuk dianalisis. Di Google Cloud, desain umum pipeline terdiri dari tiga langkah:
- Sumber data mengirim pesan dengan data ke topik Pub/Sub.
- Pub/Sub menyangga pesan dan meneruskannya ke komponen pemrosesan.
- Setelah diproses, komponen pemrosesan menyimpan data di BigQuery.
Untuk komponen pemrosesan, terdapat tiga alternatif, mulai dari dasar hingga lanjutan: langganan BigQuery, layanan Cloud Run, dan pipeline Dataflow. Mari simak ulasannya berikut.
Contoh penerapan
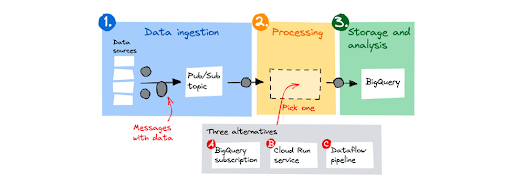 Photo Credit: Google Cloud Blog
Photo Credit: Google Cloud Blog
Tiga alternatif pemrosesan
Artikel ini akan membahas cara melakukan pemrosesan menggunakan tiga opsi berikut:
- Langganan BigQuery, solusi pass-through tanpa kode yang menyimpan pesan tidak berubah dalam set data BigQuery.
- Layanan Cloud Run, untuk pemrosesan pesan individual yang ringan tanpa agregasi.
- Pipeline Dataflow, untuk pemrosesan lanjutan.
Mari simak pembahasan untuk masing-masing pendekatan di bawah ini:
- Menyimpan data tidak berubah menggunakan langganan BigQuery
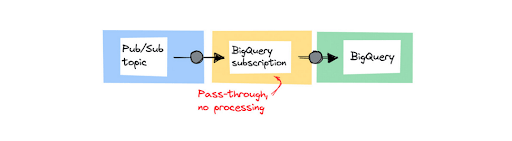 Photo Credit: Google Cloud Blog
Photo Credit: Google Cloud Blog
Pendekatan pertama adalah yang paling mudah. Anda dapat mengalirkan pesan dari topik Pub/Sub langsung ke set data BigQuery menggunakan langganan BigQuery. Gunakan saat Anda menyerap pesan dan tidak perlu melakukan pemrosesan apa pun sebelum menyimpan data. Saat menyiapkan langganan baru untuk suatu topik, pilih opsi Write to BigQuery, seperti yang ditampilkan di sini:
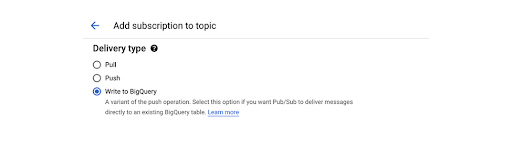 Photo Credit: Google Cloud Blog
Photo Credit: Google Cloud Blog
Detail tentang bagaimana langganan ini diimplementasikan sepenuhnya dipisahkan dari pengguna. Artinya, tidak ada cara untuk mengeksekusi kode apa pun pada data yang masuk. Ini adalah solusi tanpa kode, Anda tidak dapat menerapkan pemfilteran pada data sebelum disimpan.
Baca juga: Mengintip Layanan Baru Google Cloud: Tawarkan Fleksibilitas Tinggi bagi Pengguna
- Memproses pesan satu per satu menggunakan Cloud Run
Gunakan Cloud Run jika Anda memang perlu melakukan beberapa pemrosesan ringan pada masing-masing pesan sebelum menyimpannya. Misalnya, mengkanonikalisasi format data, di mana setiap sumber data menggunakan format dan bidangnya sendiri, tapi Anda ingin menyimpan data dalam satu format data.
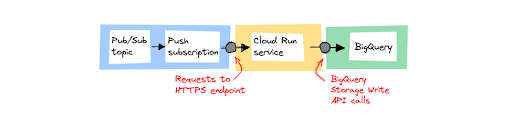 Photo Credit: Google Cloud Blog
Photo Credit: Google Cloud Blog
Pertimbangkan untuk menggunakan Cloud Run sebagai komponen pemrosesan dalam pipeline, jika:
- Anda dapat memproses pesan satu per satu, tanpa memerlukan pengelompokan dan penggabungan pesan.
- Anda lebih suka menggunakan model pemrograman umum daripada menggunakan SDK khusus.
- Anda sudah menggunakan Cloud Run untuk melayani aplikasi web dan lebih memilih arsitektur solusi yang konsisten dan simpel.
Baca juga: Melihat Contoh Penerapan Google Distributed Cloud Edge Appliance
- Pemrosesan lanjutan dan agregasi pesan menggunakan Dataflow
Cloud Dataflow, layanan yang terkelola sepenuhnya untuk mengeksekusi pipeline Apache Beam di Google Cloud, telah lama menjadi landasan pembangunan pipeline streaming di Google Cloud. Ini adalah pilihan yang baik bagi pipeline yang menggabungkan kelompok data untuk mengurangi data dan yang memiliki beberapa langkah pemrosesan.
Dalam aliran data, pengelompokan dilakukan dengan menggunakan windowing. Fungsi windowing mengelompokkan koleksi tak terbatas berdasarkan time stamp. Ada beberapa strategi windowing yang tersedia, yaitu fixed, sliding, dan session windowing. Dataflow memiliki dukungan bawaan untuk menangani data yang terlambat. Data terlambat masuk saat jendela telah ditutup, dan Anda mungkin ingin membuang data tersebut atau memulai penghitungan ulang.
Pendekatan mana yang sebaiknya dipilih?
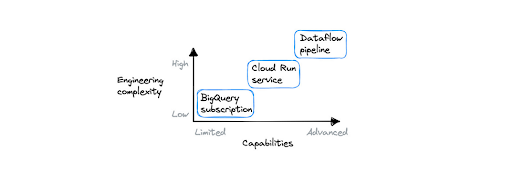 Photo Credit: Google Cloud Blog
Photo Credit: Google Cloud Blog
Ketiga pendekatan di atas memiliki kemampuan dan tingkat kerumitan yang berbeda. Dataflow adalah opsi paling andal dan paling kompleks, yang mengharuskan pengguna menggunakan SDK khusus (Apache Beam) untuk membangun pipeline mereka. Di sisi lain, langganan BigQuery tidak mengizinkan logika pemrosesan apa pun dan dapat dikonfigurasi menggunakan konsol web. Memilih alat yang paling sesuai dengan kebutuhan akan membantu Anda mendapatkan hasil yang lebih baik dengan lebih cepat.
Baca juga: Mengoptimalkan Penggunaan BigQuery BI Engine
Untuk pipeline besar (Skala Spotify), atau saat Anda perlu mengurangi data menggunakan windowing, atau memiliki multi-step pipeline yang rumit, pilih Dataflow. Dalam semua kasus lainnya, memulai dengan Cloud Run adalah yang terbaik, kecuali jika Anda sedang mencari solusi tanpa kode untuk menghubungkan Pub/Sub ke BigQuery. Dalam hal ini, pilih langganan BigQuery.
Biaya adalah faktor lain yang perlu dipertimbangkan. Cloud Dataflow menerapkan penskalaan otomatis, tetapi tidak akan menskalakan ke instance nol jika tidak ada data yang masuk. Untuk beberapa tim, ini adalah alasan memilih Cloud Run daripada Dataflow.
Untuk rangkuman dari ketiga pendekatan tersebut, Anda bisa melihat tabel berikut:
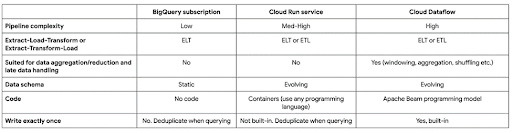 Photo Credit: Google Cloud Blog
Photo Credit: Google Cloud Blog
Google Cloud menyediakan solusi menyeluruh untuk membangun pipeline data streaming yang dapat Anda sesuaikan dengan kebutuhan dan bujet. Mulai nikmati berbagai kemudahan Cloud dengan berlangganan melalui EIKON Technology. Sebagai partner resmi Google Cloud Indonesia, kami menyediakan solusi bergaransi disertai dengan implementasi menyeluruh. Untuk informasi lebih lanjut, silakan klik di sini!